
navis
Object Separation (yolov7-pose-estimation) 본문
728x90
1. 목차
- 환경설정
- 모델 : yolov7-pose-estimation
- 코드변경
- 기존 pose-estimate.py 파일 저장경로 변경
- 추론 결과
- 결과 비교
- 최종 결과
2. 환경 설정
- AI 모델 테스트 환경
- Ubuntu 22.04(워크스테이션)
- Anaconda
- VS Code
- Python 3.8.18
- 환경설정
git clone <https://github.com/RizwanMunawar/yolov7-pose-estimation.git>
cd yolov7-pose-estimation
pip install --upgrade pip
pip install -r requirements.txt
# 가중치 다운로드
wget <https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7-w6-pose.pt> -P yolov7-pose-estimation/
3. yolov7-pose-estimation
https://github.com/RizwanMunawar/yolov7-pose-estimation
1. 모델 (yolov7-pose-estimation)

4. 코드 변경
pose-estimate.py
import os
import cv2
import time
import torch
import argparse
import numpy as np
import matplotlib.pyplot as plt
from torchvision import transforms
from utils.datasets import letterbox
from utils.torch_utils import select_device
from models.experimental import attempt_load
from utils.general import non_max_suppression_kpt, strip_optimizer, xyxy2xywh
from utils.plots import output_to_keypoint, plot_skeleton_kpts, colors, plot_one_box_kpt
@torch.no_grad()
def run(poseweights, source, device='cpu', view_img=False, save_conf=False, line_thickness=3, hide_labels=False, hide_conf=True, output_video='output_keypoint.mp4'):
frame_count = 0 # count no of frames
total_fps = 0 # count total fps
time_list = [] # list to store time
fps_list = [] # list to store fps
device = select_device(device) # select device
half = device.type != 'cpu'
model = attempt_load(poseweights, map_location=device) # Load model
_ = model.eval()
names = model.module.names if hasattr(model, 'module') else model.names # get class names
if source.isnumeric():
cap = cv2.VideoCapture(int(source)) # pass video to videocapture object
else:
cap = cv2.VideoCapture(source) # pass video to videocapture object
if not cap.isOpened(): # check if videocapture not opened
print('Error while trying to read video. Please check path again')
raise SystemExit()
else:
frame_width = int(cap.get(3)) # get video frame width
frame_height = int(cap.get(4)) # get video frame height
vid_write_image = letterbox(cap.read()[1], (frame_width), stride=64, auto=True)[0] # init videowriter
resize_height, resize_width = vid_write_image.shape[:2]
out = cv2.VideoWriter(output_video,
cv2.VideoWriter_fourcc(*'mp4v'), 30,
(resize_width, resize_height))
while cap.isOpened(): # loop until cap opened or video not complete
print("Frame {} Processing".format(frame_count + 1))
ret, frame = cap.read() # get frame and success from video capture
if ret: # if success is true, means frame exist
orig_image = frame # store frame
image = cv2.cvtColor(orig_image, cv2.COLOR_BGR2RGB) # convert frame to RGB
image = letterbox(image, (frame_width), stride=64, auto=True)[0]
image_ = image.copy()
image = transforms.ToTensor()(image)
image = torch.tensor(np.array([image.numpy()]))
image = image.to(device) # convert image data to device
image = image.float() # convert image to float precision (cpu)
start_time = time.time() # start time for fps calculation
with torch.no_grad(): # get predictions
output_data, _ = model(image)
output_data = non_max_suppression_kpt(output_data, # Apply non max suppression
0.25, # Conf. Threshold.
0.65, # IoU Threshold.
nc=model.yaml['nc'], # Number of classes.
nkpt=model.yaml['nkpt'], # Number of keypoints.
kpt_label=True)
output = output_to_keypoint(output_data)
im0 = image[0].permute(1, 2, 0) * 255 # Change format [b, c, h, w] to [h, w, c] for displaying the image.
im0 = im0.cpu().numpy().astype(np.uint8)
im0 = cv2.cvtColor(im0, cv2.COLOR_RGB2BGR) # reshape image format to (BGR)
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
for i, pose in enumerate(output_data): # detections per image
if len(output_data): # check if no pose
for c in pose[:, 5].unique(): # Print results
n = (pose[:, 5] == c).sum() # detections per class
print("No of Objects in Current Frame : {}".format(n))
for det_index, (*xyxy, conf, cls) in enumerate(reversed(pose[:, :6])): # loop over poses for drawing on frame
c = int(cls) # integer class
kpts = pose[det_index, 6:]
label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
plot_one_box_kpt(xyxy, im0, label=label, color=colors(c, True),
line_thickness=line_thickness, kpt_label=True, kpts=kpts, steps=3,
orig_shape=im0.shape[:2])
end_time = time.time() # Calculation for FPS
fps = 1 / (end_time - start_time)
total_fps += fps
frame_count += 1
fps_list.append(total_fps) # append FPS in list
time_list.append(end_time - start_time) # append time in list
# Stream results
if view_img:
cv2.imshow("YOLOv7 Pose Estimation Demo", im0)
cv2.waitKey(1) # 1 millisecond
out.write(im0) # writing the video frame
else:
break
cap.release()
# cv2.destroyAllWindows()
avg_fps = total_fps / frame_count
print(f"Average FPS: {avg_fps:.3f}")
# plot the comparison graph
plot_fps_time_comparision(time_list=time_list, fps_list=fps_list, source=source)
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--poseweights', type=str, default='./yolov7-pose-estimation/yolov7-w6-pose.pt', help='model path')
parser.add_argument('--source', type=str, default='./input/football1.mp4', help='video/0 for webcam') # video source
parser.add_argument('--device', type=str, default='cpu', help='cpu/0,1,2,3(gpu)') # device arguments
parser.add_argument('--view-img', action='store_true', help='display results') # display results
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels') # save confidence in txt writing
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)') # box line thickness
parser.add_argument('--hide-labels', action='store_true', help='hide labels') # hide labels
parser.add_argument('--hide-conf', action='store_true', help='hide confidences') # hide confidences
parser.add_argument('--output-video', type=str, default='output_keypoint.mp4', help='output video path') # output video path
opt = parser.parse_args()
return opt
# function for plot fps and time comparison graph
def plot_fps_time_comparision(time_list, fps_list, source, output_dir='evaluation'):
if not os.path.exists(output_dir):
os.makedirs(output_dir)
input_video_name = os.path.splitext(os.path.basename(source))[0]
output_path = os.path.join(output_dir, f"{input_video_name}_FPS_and_Time_Comparision.png")
plt.figure()
plt.xlabel('Time (s)')
plt.ylabel('FPS')
plt.title('FPS and Time Comparison Graph')
plt.plot(time_list, fps_list, 'b', label="FPS & Time")
plt.savefig(output_path)
print(f"FPS and Time Comparison graph saved at {output_path}")
# main function
def main(opt):
run(**vars(opt))
if __name__ == "__main__":
opt = parse_opt()
strip_optimizer(opt.device, opt.poseweights)
main(opt)input vidoe와 output video 경로 수정 및 평가지표, 체크포인트 경로만 수정하였습니다.
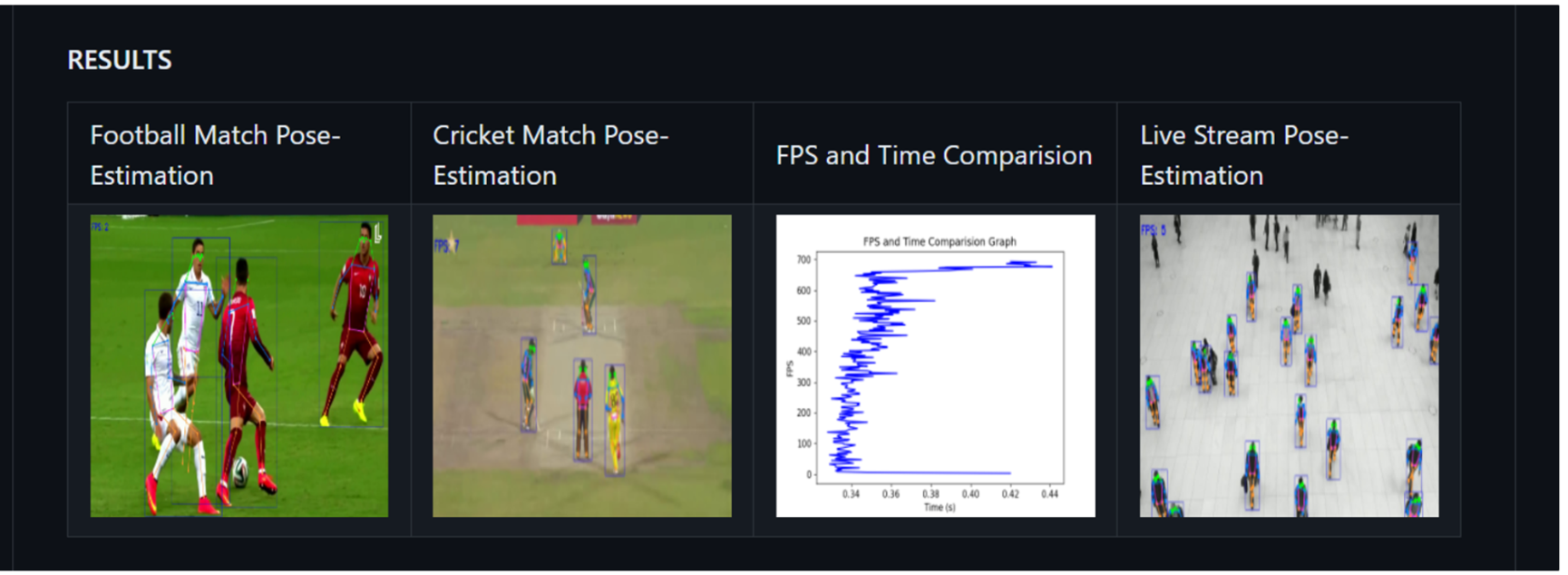
5. 추론 결과
input Video (yolov7-pose-estimation)
output Video (yolov7-pose-estimation)

6. 최종 결과
yolo에서 제공하는 인체 자세 추적 모델 테스트 진행하였습니다.
제시하는 비디오와 Test용 비디오 모두 정확하게 잡아내는 것으로 확인 되었습니다.
자체에서 동영상의 자세를 추출하기 때문에 프레임 단위로 나눌 필요는 없어 보이고 이 정보들을 수치화 해서 의복 변경하는데 접목시켜 사용 할 수 있을 것으로 보입니다.
세부적인 세팅은 필요하겠지만 인체 자세 추적은 정확도가 높은 것으로 보입니다.
'AI' 카테고리의 다른 글
| VPP (FastSAM) (0) | 2024.06.16 |
|---|---|
| VPP (yolo7-segmentation) (0) | 2024.06.16 |
| Object Separation (GVTO) (0) | 2024.06.16 |
| Video Upscaling (ResShift) (0) | 2024.06.16 |
| Video Upscaling (StableSR) (0) | 2024.06.16 |
'AI' Related Articles
more



