
navis
Video Upscaling (CodeFormer) 본문
728x90
1. 목차
- 환경설정
- 모델 : CodeFormer (Real-ESRGAN)
- 코드변경
- 기존 inference_codeformer.py 파일 input 데이터 처리하게 수정
- Fast API 통신을 위한 main.py 작성
- 추론 결과
- 결과 비교
- 최종 결과
2. 환경 설정
- AI 모델 테스트 환경
- Window 10
- Anaconda
- VS Code
- Python 3.8.18
- 환경설정
# git clone this repository
git clone <https://github.com/sczhou/CodeFormer>
cd CodeFormer
# install python dependencies
pip3 install -r requirements.txt
python basicsr/setup.py develop
conda install -c conda-forge dlib (only for face detection or cropping with dlib)
- Fast Server 설정
- Fast API
- OpenCV 4.9
- FFmpeg
- 환경설정
pip install fastapi uvicorn aiofiles
conda install -c conda-forge ffmpeg
3. VRT
https://github.com/sczhou/CodeFormer
1. 모델 (CdoeFormer)
S-Lab, Nanyang Technological University
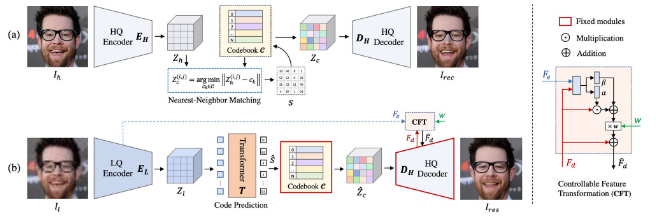
4. 코드 변경
main_test_vrt.py
import os
import cv2
import argparse
import glob
import torch
from torchvision.transforms.functional import normalize
from basicsr.utils import imwrite, img2tensor, tensor2img
from basicsr.utils.download_util import load_file_from_url
from basicsr.utils.misc import gpu_is_available, get_device
from facelib.utils.face_restoration_helper import FaceRestoreHelper
from facelib.utils.misc import is_gray
from basicsr.utils.registry import ARCH_REGISTRY
pretrain_model_url = {
'restoration': 'https://github.com/sczhou/CodeFormer/releases/download/v0.1.0/codeformer.pth',
}
def set_realesrgan():
from basicsr.archs.rrdbnet_arch import RRDBNet
from basicsr.utils.realesrgan_utils import RealESRGANer
use_half = False
if torch.cuda.is_available(): # set False in CPU/MPS mode
no_half_gpu_list = ['1650', '1660'] # set False for GPUs that don't support f16
if not True in [gpu in torch.cuda.get_device_name(0) for gpu in no_half_gpu_list]:
use_half = True
model = RRDBNet(
num_in_ch=3,
num_out_ch=3,
num_feat=64,
num_block=23,
num_grow_ch=32,
scale=2,
)
upsampler = RealESRGANer(
scale=2,
model_path="https://github.com/sczhou/CodeFormer/releases/download/v0.1.0/RealESRGAN_x2plus.pth",
model=model,
tile=args.bg_tile,
tile_pad=40,
pre_pad=0,
half=use_half
)
if not gpu_is_available(): # CPU
import warnings
warnings.warn('Running on CPU now! Make sure your PyTorch version matches your CUDA.'
'The unoptimized RealESRGAN is slow on CPU. '
'If you want to disable it, please remove `--bg_upsampler` and `--face_upsample` in command.',
category=RuntimeWarning)
return upsampler
if __name__ == '__main__':
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device = get_device()
parser = argparse.ArgumentParser()
parser.add_argument('-i', '--input_path', type=str, default='./inputs/whole_imgs',
help='Input image, video or folder. Default: inputs/whole_imgs')
parser.add_argument('-o', '--output_path', type=str, default=None,
help='Output folder. Default: results/<input_name>_<w>')
parser.add_argument('-w', '--fidelity_weight', type=float, default=1,
help='Balance the quality and fidelity. Default: 0.5')
parser.add_argument('-s', '--upscale', type=int, default=2,
help='The final upsampling scale of the image. Default: 2')
parser.add_argument('--has_aligned', action='store_true', help='Input are cropped and aligned faces. Default: False')
parser.add_argument('--only_center_face', action='store_true', help='Only restore the center face. Default: False')
parser.add_argument('--draw_box', action='store_true', help='Draw the bounding box for the detected faces. Default: False')
# large det_model: 'YOLOv5l', 'retinaface_resnet50'
# small det_model: 'YOLOv5n', 'retinaface_mobile0.25'
parser.add_argument('--detection_model', type=str, default='retinaface_resnet50',
help='Face detector. Optional: retinaface_resnet50, retinaface_mobile0.25, YOLOv5l, YOLOv5n, dlib. \
Default: retinaface_resnet50')
parser.add_argument('--bg_upsampler', type=str, default='realesrgan', help='Background upsampler. Optional: realesrgan')
parser.add_argument('--face_upsample', action='store_true', help='Face upsampler after enhancement. Default: False')
parser.add_argument('--bg_tile', type=int, default=400, help='Tile size for background sampler. Default: 400')
parser.add_argument('--suffix', type=str, default=None, help='Suffix of the restored faces. Default: None')
parser.add_argument('--save_video_fps', type=float, default=None, help='Frame rate for saving video. Default: None')
args = parser.parse_args()
# ------------------------ input & output ------------------------
w = args.fidelity_weight
input_video = False
if args.input_path.endswith(('jpg', 'jpeg', 'png', 'JPG', 'JPEG', 'PNG')): # input single img path
input_img_list = [args.input_path]
result_root = f'results/test_img_{w}'
elif args.input_path.endswith(('mp4', 'mov', 'avi', 'MP4', 'MOV', 'AVI')): # input video path
from basicsr.utils.video_util import VideoReader, VideoWriter
input_img_list = []
vidreader = VideoReader(args.input_path)
image = vidreader.get_frame()
while image is not None:
input_img_list.append(image)
image = vidreader.get_frame()
audio = vidreader.get_audio()
fps = vidreader.get_fps() if args.save_video_fps is None else args.save_video_fps
video_name = os.path.basename(args.input_path)[:-4]
result_root = f'results/{video_name}_{w}'
input_video = True
vidreader.close()
else: # input img folder
if args.input_path.endswith('/'): # solve when path ends with /
args.input_path = args.input_path[:-1]
# scan all the jpg and png images
input_img_list = sorted(glob.glob(os.path.join(args.input_path, '*.[jpJP][pnPN]*[gG]')))
result_root = f'results/{os.path.basename(args.input_path)}_{w}'
if not args.output_path is None: # set output path
result_root = args.output_path
test_img_num = len(input_img_list)
if test_img_num == 0:
raise FileNotFoundError('No input image/video is found...\n'
'\tNote that --input_path for video should end with .mp4|.mov|.avi')
# ------------------ set up background upsampler ------------------
if args.bg_upsampler == 'realesrgan':
bg_upsampler = set_realesrgan()
else:
bg_upsampler = None
# ------------------ set up face upsampler ------------------
if args.face_upsample:
if bg_upsampler is not None:
face_upsampler = bg_upsampler
else:
face_upsampler = set_realesrgan()
else:
face_upsampler = None
# ------------------ set up CodeFormer restorer -------------------
net = ARCH_REGISTRY.get('CodeFormer')(dim_embd=512, codebook_size=1024, n_head=8, n_layers=9,
connect_list=['32', '64', '128', '256']).to(device)
# ckpt_path = 'weights/CodeFormer/codeformer.pth'
ckpt_path = load_file_from_url(url=pretrain_model_url['restoration'],
model_dir='weights/CodeFormer', progress=True, file_name=None)
checkpoint = torch.load(ckpt_path)['params_ema']
net.load_state_dict(checkpoint)
net.eval()
# ------------------ set up FaceRestoreHelper -------------------
# large det_model: 'YOLOv5l', 'retinaface_resnet50'
# small det_model: 'YOLOv5n', 'retinaface_mobile0.25'
if not args.has_aligned:
print(f'Face detection model: {args.detection_model}')
if bg_upsampler is not None:
print(f'Background upsampling: True, Face upsampling: {args.face_upsample}')
else:
print(f'Background upsampling: False, Face upsampling: {args.face_upsample}')
face_helper = FaceRestoreHelper(
args.upscale,
face_size=512,
crop_ratio=(1, 1),
det_model = args.detection_model,
save_ext='png',
use_parse=True,
device=device)
# -------------------- start to processing ---------------------
for i, img_path in enumerate(input_img_list):
# clean all the intermediate results to process the next image
face_helper.clean_all()
if isinstance(img_path, str):
img_name = os.path.basename(img_path)
basename, ext = os.path.splitext(img_name)
print(f'[{i+1}/{test_img_num}] Processing: {img_name}')
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
else: # for video processing
basename = str(i).zfill(6)
img_name = f'{video_name}_{basename}' if input_video else basename
print(f'[{i+1}/{test_img_num}] Processing: {img_name}')
img = img_path
if args.has_aligned:
# the input faces are already cropped and aligned
img = cv2.resize(img, (512, 512), interpolation=cv2.INTER_LINEAR)
face_helper.is_gray = is_gray(img, threshold=10)
if face_helper.is_gray:
print('Grayscale input: True')
face_helper.cropped_faces = [img]
else:
face_helper.read_image(img)
# get face landmarks for each face
num_det_faces = face_helper.get_face_landmarks_5(
only_center_face=args.only_center_face, resize=640, eye_dist_threshold=5)
print(f'\tdetect {num_det_faces} faces')
# align and warp each face
face_helper.align_warp_face()
# face restoration for each cropped face
for idx, cropped_face in enumerate(face_helper.cropped_faces):
# prepare data
cropped_face_t = img2tensor(cropped_face / 255., bgr2rgb=True, float32=True)
normalize(cropped_face_t, (0.5, 0.5, 0.5), (0.5, 0.5, 0.5), inplace=True)
cropped_face_t = cropped_face_t.unsqueeze(0).to(device)
try:
with torch.no_grad():
output = net(cropped_face_t, w=w, adain=True)[0]
restored_face = tensor2img(output, rgb2bgr=True, min_max=(-1, 1))
del output
torch.cuda.empty_cache()
except Exception as error:
print(f'\tFailed inference for CodeFormer: {error}')
restored_face = tensor2img(cropped_face_t, rgb2bgr=True, min_max=(-1, 1))
restored_face = restored_face.astype('uint8')
face_helper.add_restored_face(restored_face, cropped_face)
# paste_back
if not args.has_aligned:
# upsample the background
if bg_upsampler is not None:
# Now only support RealESRGAN for upsampling background
bg_img = bg_upsampler.enhance(img, outscale=args.upscale)[0]
else:
bg_img = None
face_helper.get_inverse_affine(None)
# paste each restored face to the input image
if args.face_upsample and face_upsampler is not None:
restored_img = face_helper.paste_faces_to_input_image(upsample_img=bg_img, draw_box=args.draw_box, face_upsampler=face_upsampler)
else:
restored_img = face_helper.paste_faces_to_input_image(upsample_img=bg_img, draw_box=args.draw_box)
# save faces
for idx, (cropped_face, restored_face) in enumerate(zip(face_helper.cropped_faces, face_helper.restored_faces)):
# save cropped face
if not args.has_aligned:
save_crop_path = os.path.join(result_root, 'cropped_faces', f'{basename}_{idx:02d}.png')
imwrite(cropped_face, save_crop_path)
# save restored face
if args.has_aligned:
save_face_name = f'{basename}.png'
else:
save_face_name = f'{basename}_{idx:02d}.png'
if args.suffix is not None:
save_face_name = f'{save_face_name[:-4]}_{args.suffix}.png'
save_restore_path = os.path.join(result_root, 'restored_faces', save_face_name)
imwrite(restored_face, save_restore_path)
# save restored img
if not args.has_aligned and restored_img is not None:
if args.suffix is not None:
basename = f'{basename}_{args.suffix}'
save_restore_path = os.path.join(result_root, 'final_results', f'{basename}.png')
imwrite(restored_img, save_restore_path)
# save enhanced video
if input_video:
print('Video Saving...')
# load images
video_frames = []
img_list = sorted(glob.glob(os.path.join(result_root, 'final_results', '*.[jp][pn]g')))
for img_path in img_list:
img = cv2.imread(img_path)
video_frames.append(img)
# write images to video
height, width = video_frames[0].shape[:2]
if args.suffix is not None:
video_name = f'{video_name}_{args.suffix}.png'
save_restore_path = os.path.join(result_root, f'{video_name}.mp4')
vidwriter = VideoWriter(save_restore_path, height, width, fps, audio)
for f in video_frames:
vidwriter.write_frame(f)
vidwriter.close()
print(f'\nAll results are saved in {result_root}')main.py
import os
from fastapi import FastAPI, Response, Form
from fastapi import File, UploadFile
from fastapi.responses import JSONResponse, StreamingResponse, FileResponse
from fastapi.staticfiles import StaticFiles
from pydantic import BaseModel
import subprocess
import json
import shutil
from typing import Optional
from datetime import datetime
# uvicorn main:app --reload --host 192.168.0.48
# 서버 실행
def get_current_time_text():
"""Return the current time as a formatted text string."""
now = datetime.now()
time_text = now.strftime("_%Y%m%d_%H%M%S")
return time_text
app = FastAPI()
@app.get("/")
def read_root():
return {"Hello": "World"}
@app.post("/video")
async def upload_video(video: UploadFile = File(...), scaleOption: Optional[str] = Form(None)):
video_name_all = video.filename
video_file = video.file
video_name = video_name_all.split('.')[0]
extension = video_name_all.split('.')[-1]
time_name = get_current_time_text()
video_name_all = f"{video_name}{time_name}.{extension}"
input_path = f"./input_video/{video_name}/"
output_path = f"./output_video/{video_name}/"
os.makedirs(input_path, exist_ok=True)
os.makedirs(output_path, exist_ok=True)
if scaleOption:
scale_option = json.loads(scaleOption)
scale_option = str(scaleOption)
else:
scale_option = None
input_full_path = os.path.join(input_path, video_name_all)
output_full_path = os.path.join(output_path, video_name_all)
# try:
with open(input_full_path, "wb") as buffer:
while content := await video.read(1024):
buffer.write(content)
subprocess.call(['python', 'c:/lumen/upscale/CodeFormer/inference_codeformer.py',
'-i', input_full_path,
'-o', output_path,
'-s', scale_option,
'--face_upsample'
])
return FileResponse(output_full_path, media_type='video/mp4', filename=video_name_all)
# finally:
# if os.path.exists(input_path):
# shutil.rmtree(input_path)
# if os.path.exists(output_path):
# shutil.rmtree(output_path)http://192.168.0.201:5000/video 엔드포인트 경로로 Video 파일 전송시
파일저장 → 프레임 추출 → 프레임당 업스케일 → 비디오 합치기 → 리턴 순으로 진행됨
5. 추론 결과
input Video Frame (CodeFormer)
output Video Frame (CodeFormer)
6. 최종 결과
영상을 프레임 단위로 분할하여 Upscaling을 진행하는데, 이 모델 자체가 애니메이션 특화 모델이므로 애니메이션의 선들은 선명하게 재현됩니다.
그러나 인물이 등장하는 경우, 프레임마다 GAN 기반으로 이미지를 생성하므로, 해상도는 향상되었지만 각 프레임마다 이미지가 달라져 불안정한 현상을 확인할 수 있었습니다. 그럼에도 불구하고, 뒷 부분의 글씨나 다른 사물들의 품질은 많이 향상된 것으로 보입니다.
그러나 오래된 영상에 대한 Upscaling을 진행할 때는 이 모델을 사용하기 어려워 보입니다.
'AI' 카테고리의 다른 글
| Object Separation (VITON-HD) (0) | 2024.05.27 |
|---|---|
| 우분투 Anaconda Navigator 설치 및 실행 (0) | 2024.05.23 |
| Object Separation (cloth-segmentation) (0) | 2024.05.22 |
| Video Upscaling (VRT) (0) | 2024.05.22 |
| Video Upscaling (IART) (0) | 2024.05.22 |
'AI' Related Articles
more


